Sara Hooker, “The hardware lottery”, Commun. ACM 64, 12, December 2021, pp. 58-65, https://doi.org/10.1145/3467017
Synopsis
The term, Hardware Lottery, is used to define the unintentional prejudice observed historically towards certain research ideas in computer science that succeed, not because they were far superior to others but due to how well-suited they were for the available hardware and software of the time, often creating ‘noise’ to the interpretability of new research directions. The domain-specific era is even more prone to this, where the hardware landscape is getting even more fragmented. Figure 1 demonstrates this. Writing software for each system is expensive and even then chances are only those companies would succeed whose technologies can successfully be adopted to commercial applications. Specialised hardware can be replaced with the advent of newer technologies, therefore scalability and adoptability is critical to a hardware development infrastructure.
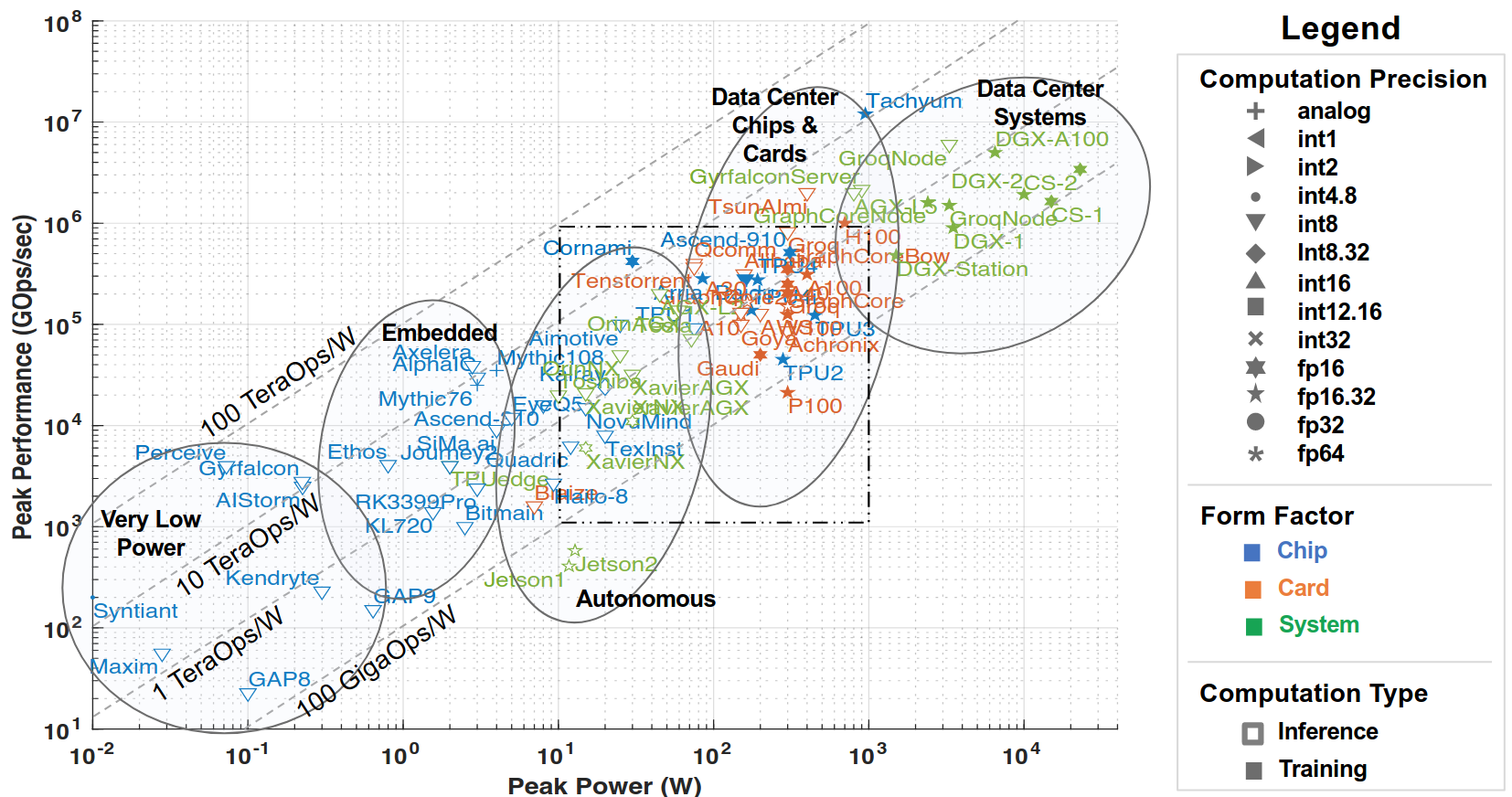 Figure 1: Peak performance vs peak power of publically announced accelerators in 2022 [arxiv:2210.04055]
Figure 1: Peak performance vs peak power of publically announced accelerators in 2022 [arxiv:2210.04055]
Strengths
The numerous examples from history from Edison’s Phonograph to modern GPUs is an eye opener and provides a broader perspective to think about the larger picture of computing hardware landscape. The presented solutions are agreed upon propositions in the research community. The emphasis on revisiting FPGAs and CGRAs for harmonising hardware development, developing better profiling tools and using AI for design space exploration is something I agree with. Secondly, just like hardware is being evolved to be highly parameterized, parameterized DSLs for reproducing results on different hardware is necessary (functional programming, and a higher abstraction level of application specification can help: e.g. Code Generating (Explainable) AI for hardware backends).
Weaknesses
The article highlights the issues that cost, limited availability, and the lack of standardisation in hardware, will make it difficult for researchers to replicate or reproduce results. One potential missing element in the article is the discussion that the difficulties in obtaining hardware resources also limits the number of researchers working on certain problems, and slowing down of progress in certain areas. It leads to a lack of diversity in the types of research being conducted, as researchers may be limited to working on problems that can be solved with the hardware they have available (not to mention, Gartner Hype Cycle). Additionally, an obstacle is technology not being available for researchers from underprivileged countries, institutions or backgrounds (IC production is Expensive!). Lastly, it could also be discussed that standardising a set of norms for developers (in academia and industry) would help mitigate the fragmented landscape, e.g. with the open-source hardware platform like RISC-V, and compiler infrastructure like LLVM/MLIR.
Thoughts
Domain-Specific era didn’t dawn until Moore’s Law and Dennard Scaling stopped to apply. It can be worth investigating the next research idea (after-domain specific) and lay a path for its integration in future, which might not apply today for immediate adoption but can be simply available when needed [1, 2]. This can be an expensive endeavour and may not succeed - “being too early is the same as being wrong” - so caution must be exercised. For academic research, some areas include, photonic accelerator, synaptic transistor, memristor array, new memory technology, neuromorphic etc. for hardware; Neurosymbolic AI, Formal Methods etc. for software. Secondly, while it is true presently that having specialised hardware can greatly accelerate the training of deep learning models, there are also other ways to address the issue of creating uniformity in the domain-specific landscape, such as algorithmic research to use general purpose hardware (not everything needs DL), using cloud computing resources, and creating cross-DSL(domain-specific language) compilers, DSE tools and open-source solutions. Lastly, one positive impact in the DS-era would be that small teams and independent researchers would be making breakthroughs with more limited resources through the use of creative solutions and open-source tools.
Takeaways
Hardware development maintained its course ever since the 90s, however software developed fast (number of ML publications since 2005). This led to hardware being abstracted away completely by software. With increasing software complexity, hardware will be a key factor that would dictate the success for a research idea [3]. Whereas for the hardware competing in the ‘bigger is better’ race, history tells us, “a deficiency in any one number of factors dooms an endeavour to failure.” A critical understanding of the hardware/software landscape, their compatibility and co-designability is therefore elemental.
- Large new neural networks would need faster development time for corresponding accelerators, some architectures would need even more constrained design than scaling systolic arrays/vector architectures e.g. [4, 5, 6] and [7].
- Accelerating development time and cost is essential for hardware engineers. Ideas like [8, 9] didn’t succeed because the cost of iteration was too high. For software, developers need to come up with creative solutions to adapt to the current norm of accelerators.
- Looking ahead is essential to progress, ideas respawn when the time is right e.g. the case of deep neural networks in software and [10, 11] for corresponding hardware. Additionally, DNNs may not be the only way forward, at some point a new technology may spawn (e.g. something that better resembles the human brain) and we may have to redo everything. Scaling and Adaptability here needs more emphasis.
- From an economist’s perspective, the law of supply and demand is at play here. In one line, “Necessity is the mother of invention”.
Favourite bits
“Our own cognitive intelligence is both hardware and software [a domain-specific computer].”
“[accelerators] Happy families are all alike, unhappy families are unhappy in their own way.”
“[bigger is better race] An apt metaphor is that we may be trying to build a ladder to the moon.”
“Scientific progress occurs when there is a confluence of factors which allows scientists to overcome the ‘stickiness’ of the existing paradigm.”
“Registering what differs from our expectations, remains a key catalyst in driving new scientific discoveries.”
“[computer chip is] inscribing words on grains of sand.”
Suggested Reading
Science in the age of selfies [12].
Case study of ISA
Krste Asanovic once said, ‘Don’t make your own ISAs.’ This is partly true in the sense that an incompatible ISA without existing software would never make it to upstream. We have observed the success of two proprietary ISAs so far, x86_64 and ARM32/64, asserting their dominance in desktop/server and mobile markets, respectively due to them being early and developing their own software ecosystem. Other ISAs of the time VAX, MIPS, SPARC etc became only moderately successful (and are now out of circulation). Why is it partly true? Because new systems, like Graphcore and Cerebras are bringing enough performance (in addition to marketing) to the table to compete in the HPC space.
References
[1] Sutton, R. The bitter lesson, 2019. URL http://www.incompleteideas.net/IncIdeas/BitterLesson.html.
[2] Welling, M. Dowestill need modelsorjust more data and compute?, 2019. URL shorturl. at/qABIY.
[3] Barham, P. and Isard, M. Machine learning systems are stuck in a rut. In Proceedings of the Workshop on Hot Topics in Operating Systems, HotOS ’19, pp. 177–183, New York, NY, USA, 2019. Association for Computing Machinery. ISBN 9781450367271. doi: 10.1145/3317550.3321441. URL https://doi.org/10.1145/3317550.3321441.
[4] Hooker, S., Courville, A., Clark, G., Dauphin, Y., and Frome, A. What Do Compressed Deep Neural Networks Forget? arXiv e-prints, art. arXiv:1911.05248, November 2019.
[5] Gale, T., Elsen, E., and Hooker, S. The state of sparsity in deep neural networks, 2019.
[6] Evci, U., Gale, T., Menick, J., Castro, P. S., and Elsen, E. Rigging the Lottery: Making All Tickets Winners. arXiv e-prints, November 2019.
[7] Zhen, D., Yao, Z., Gholami, A., Mahoney, M., and Keutzer, K. Hawq: Hessian aware quantization of neural networks with mixedprecision, 10 2019.
[8] Kingsbury, B., Morgan, N., and Wawrzynek, J. Hipnet-1: A highly pipelined architecture for neural network training, 03 1998.
[9] Sackinger, E., Boser, B. E., Bromley, J., LeCun, Y., and Jackel, L. D. Application of the anna neural network chip to high-speed character recognition. IEEE Transactions on Neural Networks, 3(3):498–505, 1992.
[10] Hinton, G. E. and Anderson, J. A. Parallel Models of Associative Memory. L. Erlbaum Associates Inc., USA, 1989. ISBN 080580269X.
[11] Rumelhart, D. E., McClelland, J. L., and PDP Research Group, C. (eds.). Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Vol. 1: Foundations. MIT Press, Cambridge, MA, USA, 1986. ISBN 026268053X.
[12] Geman, Donald, and Stuart Geman. "Science in the age of selfies." Proceedings of the National Academy of Sciences 113.34 (2016): 9384-9387.
[ Posted by Amitabh Yadav ]
[This page is optimized for printing. Please consider saving paper by refraining from printing unless absolutely necessary.]